
Optical Character Recognition, or OCR for short, is a technology that can identify individual characters and recognize words from the text. It has evolved over time due to the various challenges it has faced with as well as improvements made in its algorithms. This article takes an in-depth look at the history of optical character recognition, its core use cases, and how it has evolved over time.
What is OCR?
OCR stands for Optical Character Recognition. It is a technology that can identify individual characters and recognize words from the text. Also, OCR can defined as the process of converting images of handwritten text into machine-encoded text. Its platforms such as AlgoDocs allow automation of text extraction, making the process smoother and easier for us as users. AlgoDocs is a software that use the latest technologies of artificial intelligence and deep learning to extract data and tables from images and scanned documents and convert them into editable text.
Optical Character Recognition: An Overview
Before we take a look at the history of Optical Character Recognition, let’s see what it is and what it does. As mentioned before, Optical Character Recognition is a technology that can identify characters and recognize words. OCR works by analyzing the black-and-white text to identify the characters. Once it has done this, it will create a text file that you can then edit and manipulate. It’s important to note that unlike traditional OCR platforms, which can only recognize the characters that printed in black and white.
So any printed color or handwritten text won’t picked up by the software. Thanks to the advanced developed algorithms integrated into AlgoDocs, it can easily and efficiently extract all data such as handwritten (for example see figures 1 and 2) and tables and even complicated tables or the ones allocated on multiple pages. Also, AlgoDocs can handle even low-quality scanned images with as low dpi as 75 (see the example shown in figures 3 and 4).

Figure 1. Example of scanned handwritten uploaded to AlgoDocs.
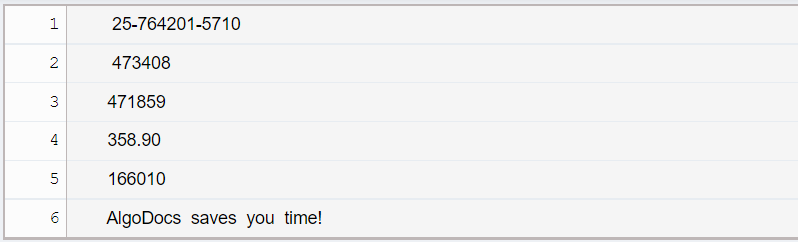
Figure 2. The extracted table after processing example shown in Figure 1. using AlgoDocs.

Figure 3. Low-quality scanned image uploaded to AlgoDocs.

Figure 4. The extracted table using AlgoDocs from the scanned image, shown in Figure 3.
Why is Optical Character Recognition Important?
OCR is an important technology as we can use OCR and we don’t need to type anything in. Just simply take a photo of a document, or scan the document and OCR will convert the file into editable text. This means that it will take less time to process a document. You can also use OCR to recognize handwriting. So OCR is an important technology for people who have many documents to deal with.
The History of Optical Character Recognition – How it has Evolved
The idea of optical character recognition dates back to the 1950s. At this time, researchers discovered that computers could programmed to recognize printed text. However, their technology only worked for printed documents, and it wasn’t very accurate. OCR technology has continued to evolve over the years. Improvements in the technology made it easier to use and allowed it to use in more industries, making it more accessible to a wider number of users. OCR technology has also become more accurate. This means that it is now more precise when it comes to reading printed documents.
In the 1960s, early research into OCR systems focused on developing techniques for recognizing individual letters in a picture. By the 1970s, more advanced systems had developed that capable of recognizing numbers, punctuation marks, and other symbols.
By the 1980s, OCR technology advanced to the point where entire words could recognized automatically. Additionally, advances in technology meant that OCR systems were no longer confined to specialized laboratories — they could be accessed online by anyone with a computer and Internet connection.
In 1994, Google developed an OCR system called Google Reader. This tool allowed users to scan and recognize text from images, improving the quality of search results on Google’s website.
By the turn of the century, OCR technology had become so efficient that it was no longer necessary for users to scan images themselves — advanced OCR systems could do this automatically for them. In 2010, Google launched Google Books as part of its effort to digitize books from around the world. The service made millions of books available without requiring any physical copies to be stored. Its OCR capabilities allowed users to search through these books electronically without needing to have a physical copy of each one.
Core Use Cases for Optical Character Recognition Technology
With the rapid growth of e-commerce and digital content, businesses need to process huge amounts of documents and files in an automated and efficient way. Optical Character Recognition (OCR) technology such as AlgoDocs can be used to extract text and tables from images and convert it into editable formats such as spreadsheets or JSON or XML.
With AlgoDocs, businesses can quickly scan and process a large amount of data without manually inputting the information. This can be a time-saving solution for businesses that deal with large amounts of documents and files.
There are many core use cases for AlgoDocs technology. Here are a few examples:
– Data extraction- AlgoDocs can process any type of document such as bank statements, invoices, HR forms & payrolls, receipts, sales & purchase orders, and price lists – AlgoDocs is commonly used to scan documents and create digital copies.
– Table extraction – AlgoDocs can be used to extract all tables even if it is allocated on multiple pages.
-Extract Handwritten Text from Scanned PDF and Images- AlgoDocs has an ICR (Intelligent Character Recognition) function that can convert handwritten text into machine-printed text.
– Convert PDF Documents to Structured JSON Objects( PDF to JSON)- AlgoDocs can extract multiple fields and tables from native and scanned PDF documents in real-time into JSON files.
Conclusion
As you can see, OCR is an important technology that has evolved over time. It has been used in a number of industries. and has helped make the process of document management and analysis easier for many users. This article has explored the history of OCR, what it is and why it is important. It has also explored the core use cases for this technology and traced the evolution of OCR over time.If you don’t try AlgoDocs yet… What are you waiting for? Now you can use the forever free subscription plan with 50 pages per month. You may check AlgoDocs pricing for paid subscriptions based on your document processing requirements.